Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook 论文笔记
摘要
在当今的IT基础设施中,持久性KV存储被广泛用作构建块,用于管理和存储大量数据。然而,由于缺乏跟踪/分析工具以及在操作环境中收集跟踪的困难,表征KV存储的真实工作负载的研究受到了限制。在本文中,我们首先对Facebook上三个典型的RocksDB生产用例的工作负载进行了详细表征:UDB(用于社交图数据的MySQL存储层)、ZippyDB(分布式KV存储)和UP2X(用于AI/ML服务的分布式KV存储)。这些特征揭示了几个有趣的发现:首先,键和值大小的分布与用例/应用程序高度相关;二是KV对的访问具有良好的局部性,并遵循一定的特殊模式;第三,收集的性能指标在UDB中显示强烈的昼夜变化模式,而其他两个没有。
我们进一步发现,尽管广泛使用的KV基准测试YCSB提供了各种工作负载配置和KV对访问分布模型,但是由于忽视键的空间局部性,YCSB触发的基础存储系统工作负载仍不足以与我们收集的工作负载接近。为了解决这个问题,我们提出了一种基于键范围的建模,并开发了一个可以更好地模拟实际KV存储的工作负载的基准测试。这个基准测试可以综合生成更精确的KV查询,表示对底层存储系统的KV存储的读写。
介绍
在当前的IT基础架构中,持久KV存储广泛用作支持各种上层应用程序的存储引擎。KV存储的高性能,灵活性和易用性吸引了更多的用户和开发人员。许多现有的系统和应用程序,例如文件系统,基于对象的存储系统,SQL数据库,甚至AI/ML系统,都使用KV存储作为后端存储来实现高性能和高空间效率。
但是,调整和提高KV存储的性能仍然具有挑战性。首先,对KV存储的实际工作负载表征和分析的研究非常有限,并且KV存储的性能与应用程序生成的工作负载高度相关。其次,表征KV存储工作负载的分析方法不同于现有的块存储或文件系统工作负载表征研究。KV存储有简单但非常不同的接口和行为。一套好的工作负载收集、分析和表征工具可以在优化性能和开发新功能方面使KV存储的开发人员和用户受益。第三,在评估KV存储的底层存储系统时,不知道KV存储基准测试生成的工作负载是否代表真实的KV存储工作负载。
为了解决这些问题,在本文中,我们在Facebook上对RocksDB(高性能持久性KV存储)的工作负载进行了表征,建模和基准测试。据我们所知,这是表征持久性KV存储工作负载的首次研究。首先,我们介绍了一套可在生产中使用的工具,用于收集KV级别的查询跟踪,重放这些跟踪以及分析跟踪。这些工具在RocksDB版本中开源,并在Facebook内用于调试和对KV存储的性能调整。其次,为了更好地理解KV工作负载及其与应用程序的相关性,我们选择了Facebook上的三个RocksDB用例进行研究:1)UDB、2)ZippyDB和3)UP2X。这三个用例是如何使用KV存储的典型例子:1)作为SQL数据库的存储引擎,2)作为分布式KV存储的存储引擎,3)作为人工智能/机器学习(AI/ML)服务的持久存储。
UDB是Facebook上社交图数据的MySQL存储层,而RocksDB被用作其后端存储引擎。社交图数据保存在MySQL表中,表行作为KV对存储在RocksDB中。从MySQL表到RocksDB KV对的转换是通过MyRocks实现的。ZippyDB是一个分布式KV存储,使用RocksDB作为存储节点来实现数据持久性和可靠性。ZippyDB通常将诸如照片元数据和对象元数据之类的数据存储在存储中。本文中,ZippyDB的工作负载是从存储了Facebook对象存储系统(论文中称为ObjStorage)元数据的分片中收集的。键通常包含ObjStorage文件或数据块的元数据,值存储了相应的对象地址。UP2X是基于RocksDB的特殊分布式KV存储。UP2X存储用于在Facebook上预测和推断多个AI/ML服务的配置文件数据(例如,计数器和统计信息)。因此,UP2X中的KV对经常更新。
基于一系列收集的工作负载,我们进一步探讨了KV存储的特定特征。根据我们的分析,我们发现1)读取在UDB和ZippyDB中占主导地位,而读-修改-写(Merge)是UP2X中的主要查询类型; 2)由于上层应用程序的键构成设计,键的大小通常很小且分布较窄,并且仅在某些特殊情况下才会出现较大的值; 3)大多数KV对是冷的(访问较少),只有很少一部分KV对是经常访问的; 4)Get,Put和Iterator具有很强的键空间局部性(例如,频繁访问的KV对位于键空间中相对较近的位置内),并且与上层应用程序的请求位置密切相关的某些键范围非常热(经常访问); 5)与ZippyDB和UP2X中的访问方式不同,UDB中的访问方式明确地表现为昼夜变化模式。
基准测试被广泛地用于评估KV存储的性能和测试存储系统。通过对真实世界的跟踪,我们将研究现有的KV基准测试是否可以综合生成具有类似特性的存储I/O的真实世界工作负载。YCSB是最广泛使用的KV基准测试之一,并已成为KV存储基准测试的黄金标准。它提供了不同的工作负载模型、各种查询类型、灵活的配置,并支持大多数广泛使用的KV存储。YCSB可以帮助用户以一种方便的方式模拟真实的工作负载。然而,我们发现,尽管YCSB可以生成具有类似ZippyDB工作负载中所示的KV查询统计信息的工作负载,但RocksDB存储I/O可能非常不同。这个问题主要是由YCSB生成的工作负载忽略了键的空间局部性造成的。在YCSB中,热KV对要么在整个键空间中随机分配,要么聚集在一起。这导致存储中访问的数据块和与KV查询关联的数据块之间的I/O不匹配。如果不考虑键的空间局部性,基准测试产生的工作负载将导致RocksDB有更大的读放大和更小的写放大,相比于真实世界工作负载。
为了开发可以更精确地模拟KV存储工作负载的基准,我们提出了一种基于键范围的热度的工作负载建模方法。整个键空间被划分为较小的键范围,并且我们对这些较小的键范围的热度进行建模。在新的基准测试中,将根据键范围热度的分布将查询分配给键范围,并且在每个键范围中热键将被紧密地分配。在我们的评估中,在相同配置下,与实际工作负载相比,YCSB导致读取字节至少增加500%,并且在RocksDB中仅提供17%的缓存命中。 由我们提出的新基准测试产生的工作负载仅增加了43%的读取字节,并实现了RocksDB中约77%的缓存命中,因此与实际工作负载更加接近。 此外,我们以UDB为例,说明新基准测试生成的综合工作负载在键/值大小,KV对访问和迭代器扫描长度方面具有良好的分布。
本文组织如下。首先,我们将在第2节中介绍RocksDB以及三个RocksDB用例的系统背景。我们将在第3部分中描述我们的方法和工具。这三个用例的详细工作负载特征(包括通用查询统计信息、键和值大小以及KV对访问分布)分别在4、5和6中给出。在第7节中,我们展示了YCSB存储统计数据的调查结果,并描述了提出的新的建模和基准测试方法。我们也比较了YCSB和新基准的结果。相关工作描述在第8节中,我们在第9节中总结了论文。
背景
在本节中,我们首先简要介绍KV存储和RocksDB。然后,我们提供了Facebook、UDB、ZippyDB和UP2X上的三个RocksDB用例的背景知识,以促进对它们工作负载的理解。
KV存储和RocksDB
KV存储是一种基于{key,value}对存储和访问数据的数据存储。键唯一地标识KV对,并且值保存数据。KV存储被公司广泛用作分布式哈希表(例如Amazon Dynamo),内存数据库(例如Redis)和持久性存储(例如Google的BigTable和Facebook的RocksDB)。
RocksDB是Facebook源自LevelDB的高性能嵌入式持久KV存储,并针对诸如SSD之类的快速存储设备进行了优化。许多大型网站也使用RocksDB,例如阿里巴巴,雅虎和LinkedIn。 在Facebook上,RocksDB用作多种数据存储服务的存储引擎,例如MySQL,Laser,Cassandra,ZippyDB和AI/ML平台。
RocksDB支持KV接口,例如Get,Put,Delete,Iterator,SingleDelete,DeleteRange和Merge。Get,Put和Delete分别用于读取,写入和删除具有特定键的KV对。Iterator用于从开始键开始扫描一组连续的KV对。扫描方向可以是向前(调用Nexts)或向后(调用Prevs)。SingleDelete仅可用于删除尚未被覆盖的KV对。DeleteRange用于删除[start, end)之间的键范围(删除中不包含结束键)。RocksDB将读取-修改-写入的语义封装到称为Merge的简单抽象接口中,这避免了在每次Put之前随机获取Get的性能开销。Merge将写入delta的增量存储到RocksDB中,并且可以堆叠或合并这些增量。这会导致较高的读取开销,因为“获取一个键”需要查找并合并所有以前存储的增量与Merge插入的相同键。Merge功能由用户定义为RocksDB插件。
RocksDB采取一个LSM-Tree来维护持久存储的KV对。RocksDB的基础架构如Figure 1所示。一个RocksDB维持至少一个逻辑分区,即列族,它有自己的内存写缓冲区(Memtable)。当一个Memtable满了,它被刷到文件系统并存储为Sorted Sequence Table文件(SST)。SST文件以排序的方式持久存储KV对,并按从Level-0开始的一系列levels进行组织。当一个级别达到其极限时,将选择一个SST文件与下一个级别具有重叠键范围(称为Compaction)的SST文件合并。
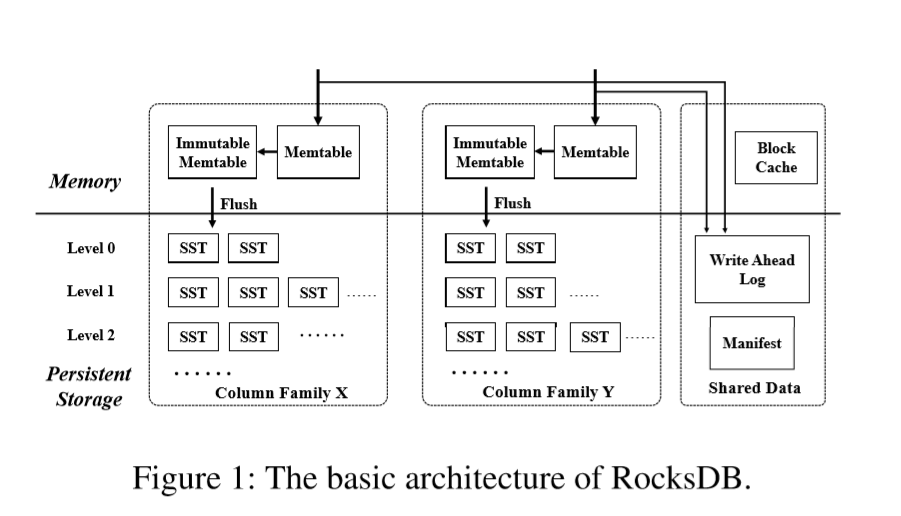
三个RocksDB用例的背景
我们讨论了RocksDB在Facebook的三个重要的大规模生产用例:1)UDB 2)ZippyDB 3)UP2X。在所有三个用例中都使用了切分来实现负载平衡。因此,所有切片的工作负载非常相似,我们从每个用例中随机选择三个RocksDB实例来收集跟踪。
UDB
Facebook上的社交图数据永久存储在分片的MySQL数据库层中。缓存读取未命中以及对社交图数据的所有写入均由UDB服务器处理。UDB依靠MySQL实例来处理所有查询,并且这些查询通过MyRocks转换为RocksDB查询。许多社交图数据都以对象和关联的形式表示,并根据模型保存在不同的MySQL表中。RocksDB使用不同的列族来存储对象和关联相关的数据。
在UDB中有6个主要的列族:Object,Assoc,Assoc_count,Object_2ry,Assoc_2ry和Non_SG。Object存储社交图对象数据,而Assoc存储社交图关系数据,关系定义了两个对象的连接。Assoc_count存储每个对象的关系数量。关系计数器总是被更新成新的值并且没有任何删除。Object_2ry和Assoc_2ry是维护对象和关系各自的二级索引的列族。他们还用于ETL。Non_SG存储来自其他非社交图相关服务的数据。
由于UDB工作负载是一个从SQL查询转换而来的KV查询的示例,因此存在一些特殊的模式。我们收集了14天的踪迹。由于三个UDB服务器的工作负载特征非常相似,所以我们只给出其中一个。此服务器中的跟踪文件总大小约为1.1TB。对于某些特性,日常数据更为重要。因此,我们还分别分析了14天时间段(24小时跟踪)中最后一天的工作负载。
ZippyDB
在RocksDB的基础上开发了高性能分布式KV存储,并依靠Paxos实现数据的一致性和可靠性。KV对被划分为切片,每个切片由一个RocksDB实例支持。选择一个副本作为切片,其他副本作为次要切片。主切片处理对某个切片的所有写操作。如果读取需要强一致性,则读取请求(如Get和Scan)仅由主切片处理。一个ZippyDB查询被转换为一组RocksDB查询(一个或多个)。
与UDB用例相比,ZippyDB中的上层查询直接映射到RocksDB查询,因此ZippyDB的工作负载特征非常不同。我们随机选取了ZippyDB的三个主切片,收集了24小时的踪迹。像UDB一样,我们只展示其中的一个。这个切片存储ObjStorage的元数据,ObjStorage是Facebook的一个对象存储系统。在这个分片中,一个KV对通常包含一个ObjStorage文件或一个数据块及其地址信息的元数据信息。
UP2X
Facebook使用各种AI/ML服务来支持社交网络,并且大量动态变化的数据集(例如用户活动的统计计数器)用于AI/ML预测和推理。UP2X是一种分布式KV存储,专门用于将这种类型的数据存储为KV对。当用户使用Facebook服务时,UP2X中的KV对会经常更新,例如计数器增加时。如果UP2X在每个Put之前调用Get来实现读-修改-写操作,由于随机Get的速度相对较慢,它将产生很高的开销。UP2X利用RocksDB Merge接口避免在更新过程中获取Gets。
UP2X中的KV对被划分为RocksDB实例支持的分片。我们从UP2X中随机选择了三个RocksDB实例,然后收集并分析了24小时跟踪。 请注意,在Compaction期间,通过Compaction过滤器清除了由Merge插入的KV对。Compaction过滤器在Compaction期间使用自定义逻辑在后台删除或修改KV对。 因此,即使不使用删除操作(例如Delete,DeleteRange和SingleDelete),也会从UP2X中删除大量KV对。
方法和工具集
为了从不同用例分析和描述RocksDB工作负载,并生成合成工作负载,我们提出并开发了一组KV存储的跟踪、回放、分析、建模和基准测试工具。这些工具已经在RocksDB发行版中开源了。在本节中,我们将介绍这些工具,并讨论如何使用它们来描述和生成KV存储的工作负载。
跟踪
跟踪工具在RocksDB公共KV接口收集查询信息,并作为记录写入跟踪文件。它在每个跟踪记录中存储以下五种类型的信息:1)查询类型,2)列族ID, 3)键,4)特定查询数据,5)时间戳。对于Put和Merge,我们将值信息存储在特定查询数据中。对于像Seek和SeekForPrev这样的迭代器查询,扫描长度(在Seek或SeekForPrev之后调用的Next或Prev的数量)存储在特定查询数据中。时间戳是在以微秒级的精度调用RocksDB公共接口时收集的。为了在跟踪文件中记录每个查询的跟踪记录,使用了一个锁来序列化所有查询,这可能会导致一些性能开销。但是,根据正常生产工作负载下的生产性能监视统计数据,我们没有观察到跟踪工具会导致主要吞吐量下降或延迟增加。
跟踪重放
收集到的跟踪文件可以通过在db_bench中实现的Replayer工具进行重放。重播工具根据跟踪记录信息向RocksDB发出查询,查询之间的时间间隔遵循跟踪中的时间戳。通过设置不同的快进和多线程参数,RocksDB可以对不同强度的工作负载进行基准测试。但是,多线程不能保证查询顺序。Replayer生成的工作负载可以看作是真实世界的工作负载。
跟踪分析
使用收集的跟踪进行回放有其局限性。由于工作负载跟踪的潜在性能开销,很难跟踪大规模和持久的工作负载。此外,跟踪文件的内容对用户/所有者来说是敏感和保密的,因此RocksDB用户很难与其他RocksDB开发人员或来自第三方公司的开发人员(例如,上层应用程序开发人员或存储供应商)共享跟踪,以进行基准测试和性能调优。为了解决这些限制,我们提出了一种分析RocksDB工作负载的方法,该方法根据跟踪中的信息对工作负载进行概要分析。
跟踪分析工具读取跟踪文件并提供以下特征:1)每个CF中的KV对、查询编号和查询类型的详细统计摘要;2)键大小和值大小统计;3)KV对的流行程度;4)键空间局部性,将访问的键与数据库中现有的键按排序顺序进行组合;和5)查询每秒(QPS)统计。
建模与基准测试
我们首先计算任意两个选定变量之间的皮尔逊相关系数,以确保这些变量具有非常低的相关性。这样,可以分别对每个变量建模。然后,我们将收集到的工作负载拟合到不同的统计模型中,找出哪个拟合误差最低,这比总是将不同的工作负载拟合到同一模型更准确。然后,提出的基准可以基于这些概率模型生成KV查询。细节将在第7节中讨论。
工作负载的一般统计
本节中,我们介绍每个用例的一般工作负载统计信息,包括每个CF中的查询组成,KV对热度分布和每秒查询。
查询组成
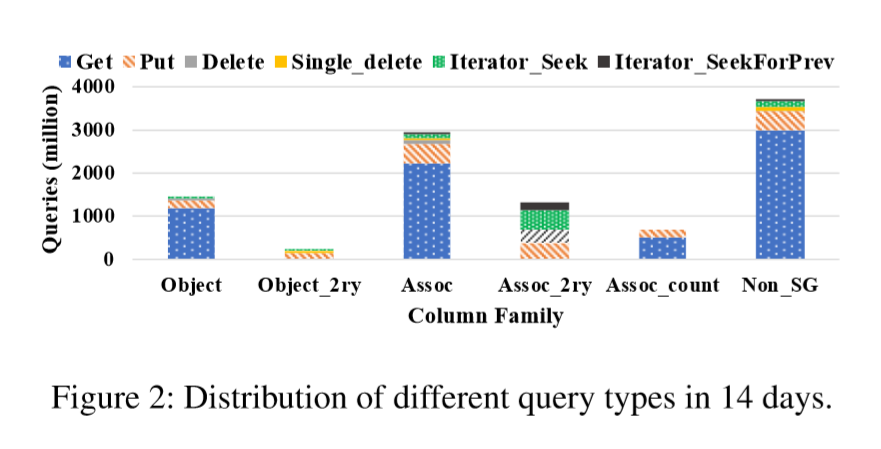
通过分析查询组成,我们可以计算出查询强度、不同用例中查询类型的比率以及查询的流行度。我们发现:1)Get在UDB和ZippyDB中是使用最频繁的查询类型,而Merge在UP2X中占主导地位;2)查询组成在不同的CFs中可能有很大的不同。
UDB
如下图Figure 2所示,存储在相同RocksDB的不同列族,他们的工作负载是很不一样的。如果没有分离不同的列族,很难对这种混合工作负载进行分析和建模。
ZippyDB
只有一个列族被用在ZippyDB上。Get是ZippyDB上的主要查询类型,它与ObjStorage的读密集型工作负载保持一致。
UP2X
UP2X的查询组成与读主导的UDB/ZippyDB完全不同。读-修改-写(Merge)是UP2X的主要工作负载模式。
KV对热度分布
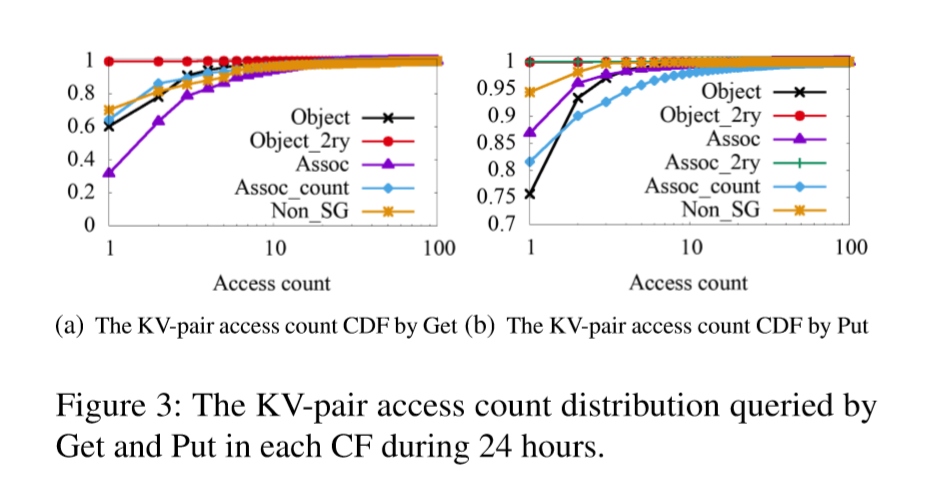
为了了解每个案例中KV对的热度,我们计算了在24小时跟踪期内每个KV对被访问了多少次,并以累积分布函数(CDF)图显示了它们。 X轴是访问计数,Y轴是0和1之间的累加比。我们发现,在UDB和ZippyDB中,大多数KV对都是冷的。
UDB
Get和Put的KV对访问计数CDF如下图Figure 3所示。从图3(a)中可以看出,在Assoc中,超过70%的KV对是至少发生2次的Get请求,而其他的列族都不超过40%,这说明Assoc的读miss比其他列族更加频繁。从图3(b)可以看出所有列族的写miss都很小,这是因为大多数KV对都很少更新。
24小时内start-keys of Iterators的访问计数CDF如下图Figure 4所示。大多数start-keys只被使用一次,显示了一个低的访问局部性。扫描长度非常大(大于10,000)非常罕见,但是我们仍然可以在Non_SG和Assoc中找到这种类型的一些示例。

不同时间段内被访问的唯一键的数量如下表Table 1所示。在过去的24小时不到3%的键被访问。在过去的14天,所有列族的比例仍低于15%。所以在这个用例中,RocksDB的大部分键是冷的。一方面,大多数读取请求由上层缓存层响应,只有读miss会触发RocksDB的查询。另一方面,社交媒体数据具有很强的时间局部性。人们可能会访问Facebook上最近发布的内容。

ZippyDB
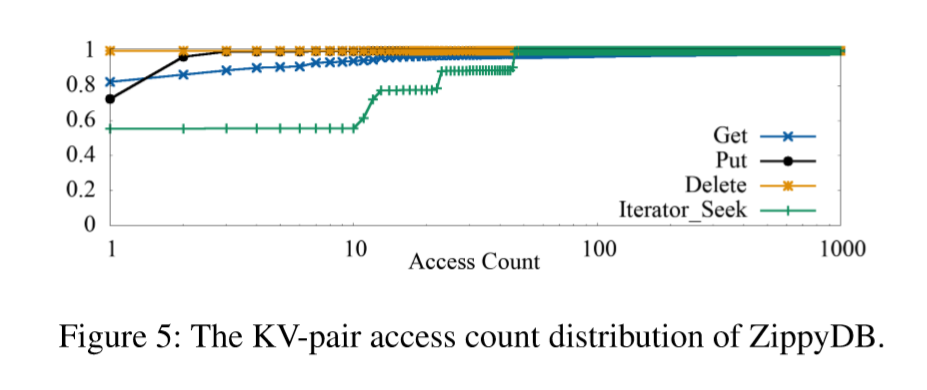
访问计数分布如下图Figure 5所示。读取查询显示了非常好的局部性,而大多数KV对只在过去24小时内Put和Delete一次。对Iterator_seek的start-keys访问很特殊,这是由于ObjStorage中元数据扫描请求造成的。例如,如果一个KV对存储了文件的第一个块的元数据,那么当请求整个文件时,它总是被用作Iterator_seek的start_key。
UP2X
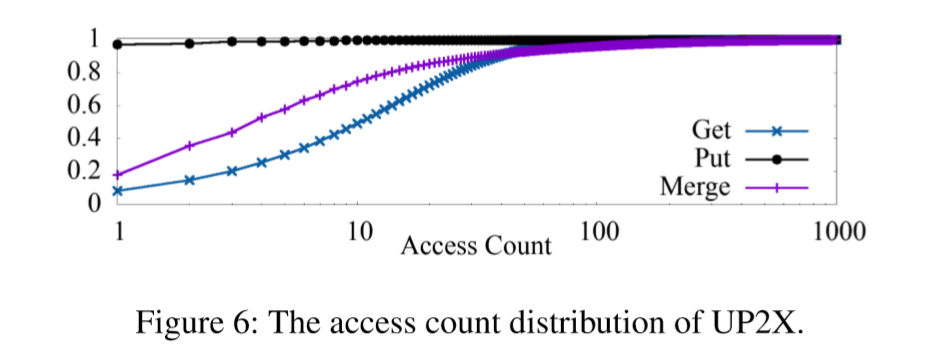
KV对访问计数的CDF分配如下图Figure 6所示。Merge和Get有广泛的访问计数分布。如果我们定义KV对在24小时内访问10次以上为热的KV对,那么通过Get访问的大约50%的KV对和通过Merge访问的25%的KV对是热的。
QPS
QPS度量显示了工作负载随时间变化的强度。部分列族在UDB中QPS具有较强的昼夜变化规律,而ZippyDB和UP2X中QPS的昼夜变化较小。每日QPS的变化与社交网络行为有关。
UDB
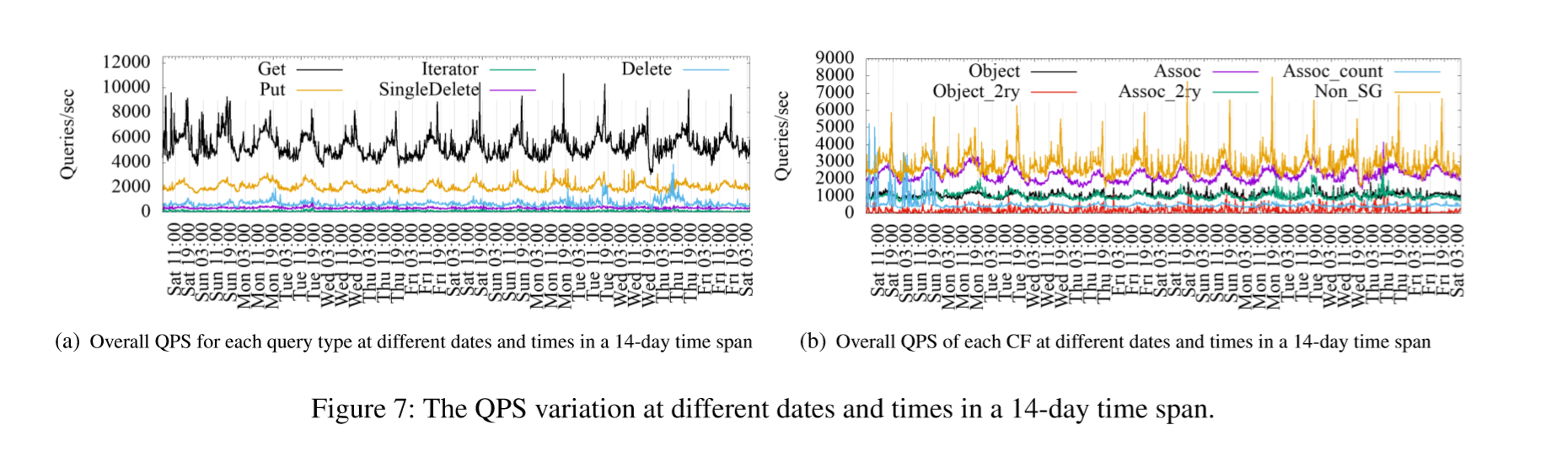
由于世界各地Facebook用户的行为,某些列族(例如Assoc和Non_SG)和某些查询类型(例如Get和Put)具有很强的昼夜模式。如图7(a)所示,Get或Put的QPS通常从大约8:00 PST开始增加,并在大约17:00 PST达到峰值。然后,QPS迅速下降并在太平洋标准时间23:00左右达到最低点。Delete,SingleDelete和Iterator的QPS会显示变化,但很难观察到任何昼夜模式,这些查询是由Facebook内部服务触发的,与用户行为的相关性较低,六个列族的QPS如图7所示(b)。Assoc和Non_SG的昼夜变化很大,但Non_SG的QPS更加尖锐。由于ETL请求不是由Facebook用户触发的,因此Object_2ry的QPS很尖刻,我们无法找到任何清晰的模式。
ZippyDB
ZippyDB的QPS与UDB不同。ZippyDB的QPS在24小时内变化,但是我们没有发现昼夜变化模式,尤其是对于Put,Delete和Iterator_Seek。由于ObjStorage是存储在Facebook上的对象,因此对象读取与社交网络行为有关。因此,Get的QPS在晚上相对较低,而在白天则相对较高(基于特定的标准时间)。由于范围查询(Iterator_Seek)通常不是由Facebook用户触发的,因此该查询类型的QPS是稳定的,并且大多数时候在100到120之间。
UP2X
UP2X中的Get或Put的QPS没有很强的昼夜变化模式。但是,Merge的使用与Facebook用户的行为密切相关,例如查看帖子,喜欢和其他操作。因此,Merge的QPS在晚上相对较低(约1000),在白天较高(约1500)。
键和值的大小
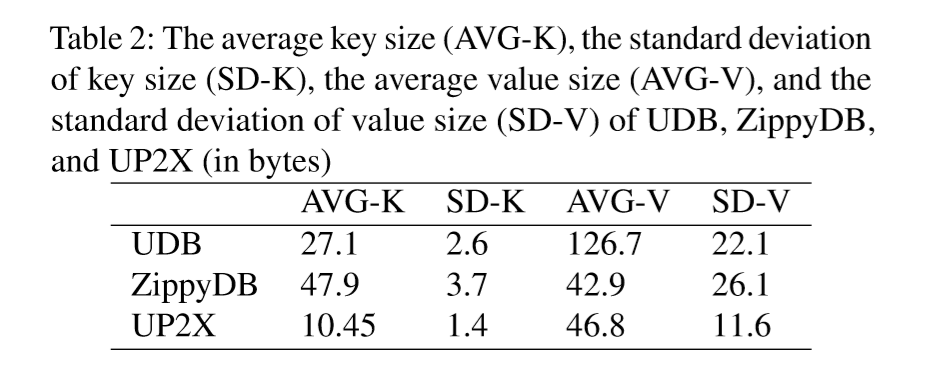
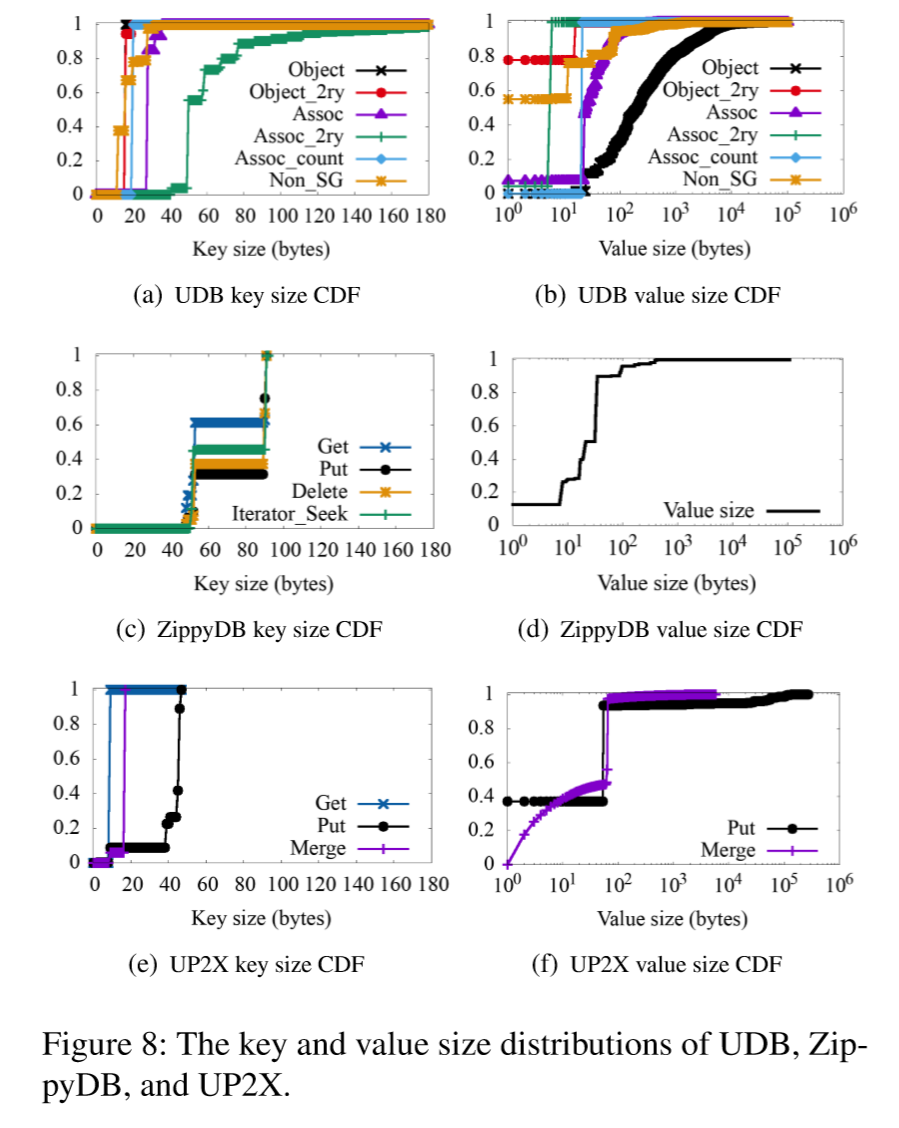
键大小和值大小是了解KV存储工作负载的重要因素。它们与性能和存储空间效率密切相关。表2中显示了键和值大小的平均值(AVG)和标准偏差(SD),图8显示了键和值大小的CDF。总体来说键大小通常很小,并且分布较窄,而值大小与数据类型密切相关。键大小的标准偏差相对较小,而值大小的标准偏差较大。UDB的平均值大小大于其他两个值。
键的空间和时间模式
RocksDB中的KV对被排序并存储在SST文件中。为了理解和可视化键空间位置,我们按照存储在RocksDB中的顺序对所有现有键进行排序,并绘制出每个KV对的访问计数,这称为整个键空间的热图。每个现有的键被分配一个唯一的整数作为其键id,基于其排序顺序并从0开始。我们将这些键id称为键序列。
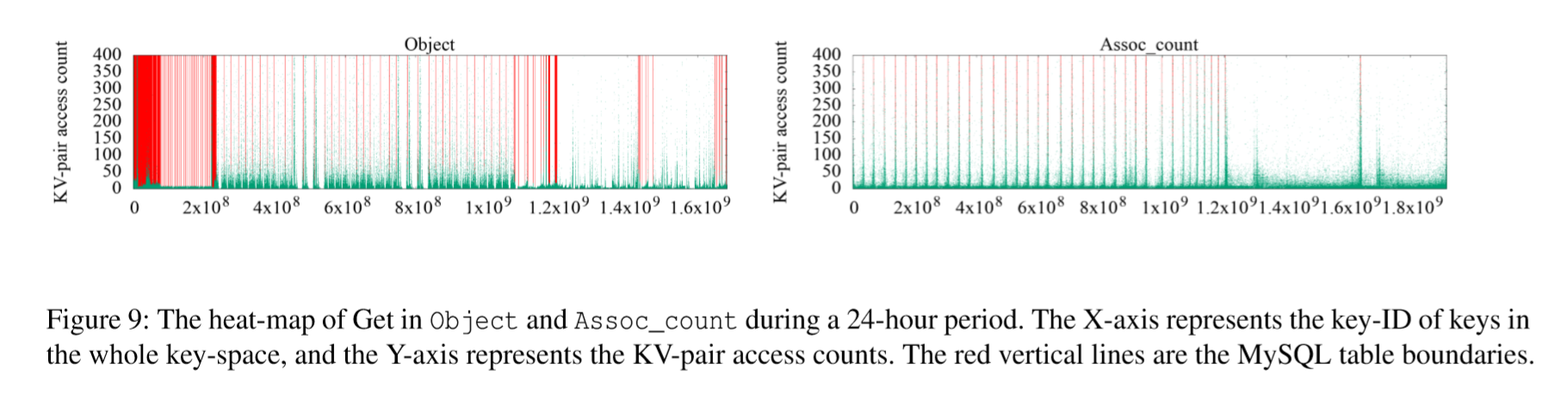
KV对访问显示了一些特殊的时间模式。例如,一些KV对在短时间内被密集访问。为了理解时间模式和键空间局部性之间的关系,我们使用时间序列顺序来可视化这些模式。我们按升序对键排序,并按照前面讨论的键id为它们分配键,这个键序列用作x轴。y轴显示调用查询的时间。为了简化y轴值,我们将每个查询的时间戳相对于跟踪的开始时间移动。时间序列图中的每个点表示当时对某个键的请求。在UDB用例中,根据MyRocks的键组成,键的前4字节是MySQL表索引号。我们用红色竖线将键空间分隔为属于不同表的不同键范围。
三个用例的热图显示了很强的键空间局部性。热KV对紧密地位于键空间中。UDB的Delete和Single Delete,UP2X的Merge的时间序列图显示了很强的时间局部性。对于某些查询类型,某些键范围中的KV对会在短时间内被大量访问。
UDB
我们使用Object和Assoc_count中Get操作在24小时内的热图作为示例来显示键空间局部性,如下图Figure 9所示。热KV对(具有高访问计数)通常位于一个小的键范围内,彼此接近。也就是说,它们显示了一个很强的键空间局部性(由稠密的绿色区域表示)。一些MySQL表(红色竖线之间的键范围)非常热(例如,Object中的绿色稠密区域),而其他表没有KV对访问。
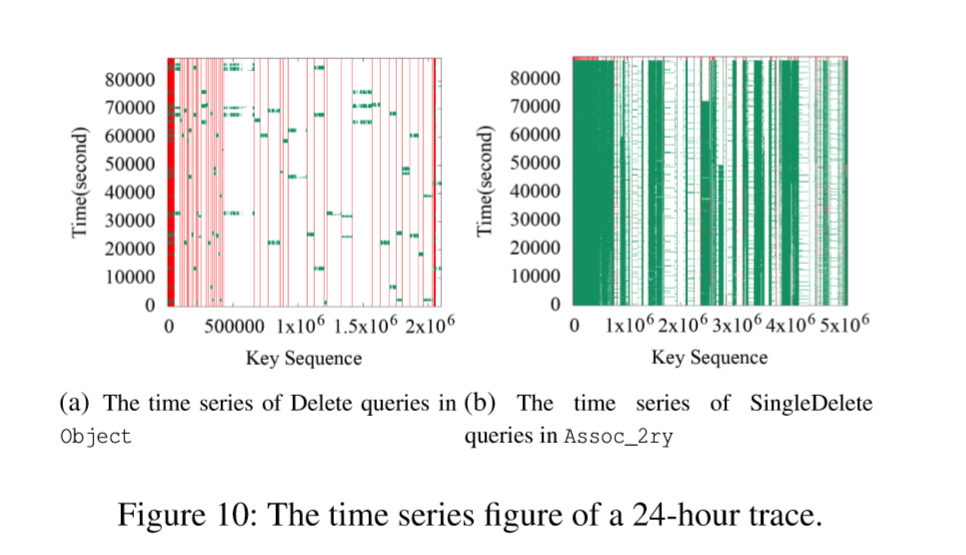
大多数KV对仅删除一次,因此不太可能重新插入。因此,在Delete和SingleDelete查询中没有热的KV对。但是,它们显示了一些特殊的模式。例如,附近的一些KV对在短时间内被删除,如图10所示。
通常,不会在整个键空间中随机访问KV对。大多数KV对不被访问或访问次数很少。 KV对中只有一小部分非常热。这些模式出现在整个键空间中,并且出现在不同的键范围内。属于同一MySQL表的KV对物理上存储在一起。不同级别的一些SST文件或同一SST文件中的数据块非常热。因此,Compaction和缓存机制可以相应地进行优化。
ZippyDB
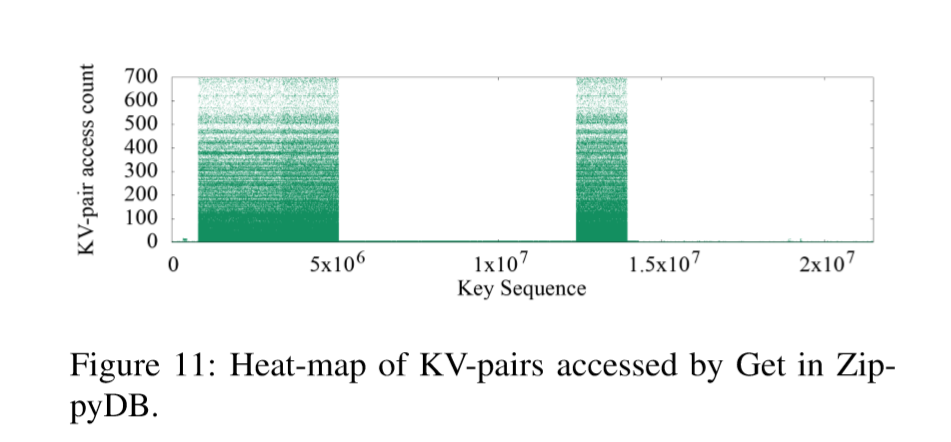
ZippyDB中的Get热图显示了很好的键空间局部性,如下图Figure 11所示。Get访问的KV对具有较高的访问计数,并且集中在几个关键范围内(例如1×106和5×106之间)。热KV对不是随机分布的,相反,这些KV对集中在几个小的关键范围内。通常,ZippyDB工作负载是读取密集型的,并且具有非常好的键空间局部性。
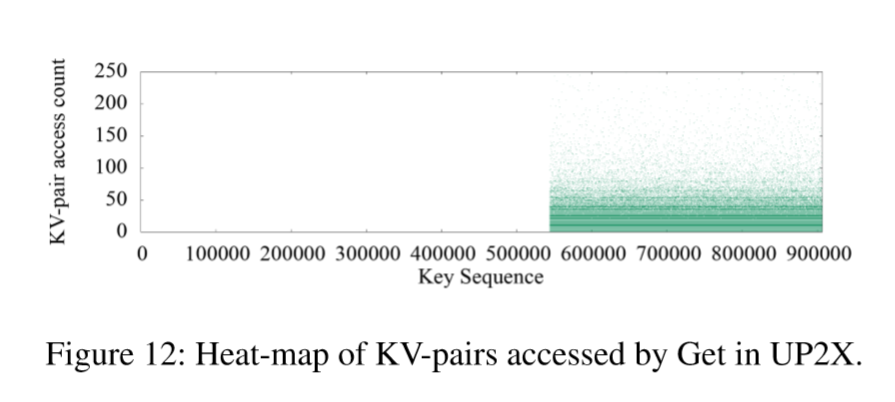
UP2X
下图Figure 12中所示的Getas访问的所有KV对的热图,我们可以在热和冷KV对之间找到清晰的边界。这种特殊的局部性可能是由AI/ML服务及其数据更新模式的独特行为引起的。
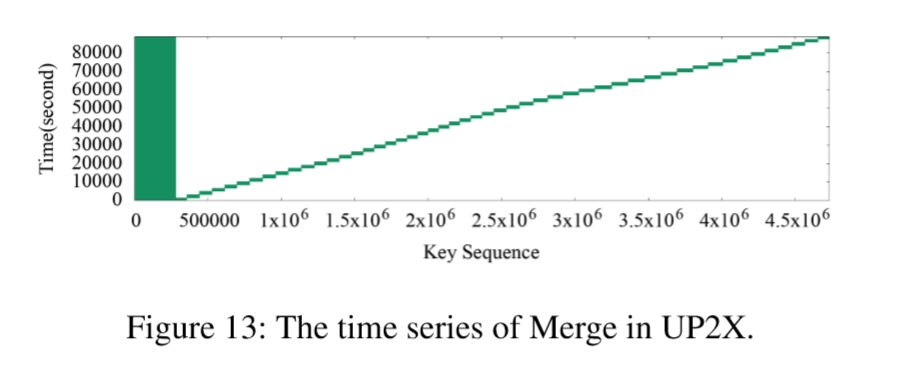
UP2X用例在Merge中显示了非常强大的键空间局部性和时间局部性。但是,Merge插入的KV对中约有90%实际上是在Compaction过程中清理的。由于键空间热图未显示通过Compaction清除的KV对的存在,因此我们绘制了Merge的时间序列顺序,这可以指示所有KV对的Merge访问,如下图Figture 13所示。绿色块表示一小部分KV对在半小时内被Merge集中调用。在此之后,在接下来的半个小时内,Merge将密集地访问一组新的KV对(具有增量组成的键)。这些KV对在Compaction时被清楚。
建模和基准测试
在理解了一些现实工作负载的特征之后,我们进一步研究是否可以使用现有的基准测试来建模和生成接近这些现实工作负载的KV工作负载。我们不在当前模型中的考虑删除。
现有的基准测试有多好?
一些研究使用YCSB/db_bench + LevelDB/RocksDB来基准测试KV存储的存储性能。研究人员通常认为YCSB产生的工作量接近于实际工作量。对于实际的工作负载,YCSB可以针对给定的查询类型比率,KV对热度分布和值大小分布生成具有相似统计信息的查询。但是,尚不清楚它们在实际工作负载中生成的工作负载是否与基础存储系统的I/O相匹配。
为了对此进行调查,我们集中于存储I/O统计信息,例如由RocksDB中的perf_stat和io_stat收集的块读取,块缓存命中,读取字节和写入字节。为了排除可能影响存储I/O的其他因素,我们重放跟踪并在干净的服务器中收集统计信息。基准测试也在同一服务器中进行评估,以确保设置相同。为确保重放期间生成的RocksDB存储I/O与生产环境中的I/O相同,我们在收集跟踪的同一RocksDB的快照中重放跟踪。快照是在我们开始跟踪时创建的。YCSB是NoSQL应用程序的基准测试,而ZippyDB是典型的分布式KV存储。因此,预期YCSB生成的工作量接近ZippyDB的工作量,我们以ZippyDB为例进行调查。由于特殊的插件要求以及UDB和UP2X的工作量复杂性,我们没有分析这两个用例的存储统计信息。
分析结果表明用YCSB的基准测试结果来指导生产可能会产生一些误导的结果。例如,RocksDB在生产工作负载下的读取性能将高于我们使用YCSB测试的性能。由于其极高的读取放大,其工作负载很容易达到存储带宽的限制。而且,从他们的基准测试结果估计的写放大低于实际生产。写性能可能被高估,还可能导致不正确的SSD生存期估计。
通过详细的分析,我们发现导致这种严重的读放大和较少的存储写入的主要因素是忽视了键空间局部性。当RocksDB遇到高速缓存未命中时,它会从存储到内存读取数据块(例如16 KB)而不是KV对。在YCSB中,即使整个KV对的热度遵循实际工作负载的分布,实际上,这些热KV对实际上是随机分布在整个键空间中。对这些热KV对的查询使大量数据块变热。由于缓存空间的限制,包含请求的KV对的大量热数据块将不会被缓存,这会触发大量的块读取。相比之下,在ZippyDB中,热KV对仅出现在一些键范围,因此热数据块的数量要少得多。类似地,热KV对的随机分布会导致更多更新的KV对在Compaction期间被垃圾回收到较新的级别。因此,正在更新的冷KV对的旧版本在较新的级别中被更早地删除,这导致在压缩较旧的级别时写入较少。相反,如果只有一些关键字范围频繁更新,则冷KV对的旧版本将不断压缩到较旧的级别,直到它们在Compaction期间与其更新。这会导致在Compaction期间写入更多数据。
基于键范围的建模
与YCSB生成的工作负载不同,现实世界的工作负载根据第6节中介绍的工作负载特征表现出很强的键空间局部性,热KV对通常集中在几个键范围内。因此,为了更好地模拟真实的工作负载,我们提出了一种基于键范围的模型。整个键空间被划分成几个较小的键范围。我们不再仅仅基于整个键空间统计数据对KV对访问进行建模,而是关注这些键范围的热度。
如何确定键范围的大小(键范围内KV对的数量)是基于键范围建模的主要挑战。如果键范围非常大,则热KV对仍会分散在很大的范围内。对这些KV对的访问仍可能触发大量数据块读取。如果键范围非常小,则热KV对实际上位于不同的键范围内,这会倒退成与不考虑键范围的模型有相同的限制。根据我们的调查,当键范围大小接近SST文件中KV对的平均数目时,它可以保留数据块级别和SST级别的局部性。因此,我们使用每个SST文件的平均KV对数作为键范围大小。
我们首先将键大小,值大小和QPS的分布适配到不同的数学模型(例如,幂,指数,多项式,Webull,Pareto和正弦),然后选择拟合标准误差(均方根误差)最小的模型。对于ZippyDB收集的工作负载,键大小固定为48或90字节,值大小遵循广义Pareto分布,QPS可以在24小时内以较小的振幅更好地拟合余弦或正弦。
然后,根据KV对访问计数及其在整个键空间中的顺序,计算每个键范围的每个KV对的平均访问,并拟合到分布模型(例如,幂分布)。这样,当生成一个查询时,我们可以计算每个键范围对此查询作出响应的概率。在每个键范围内,我们让KV对访问计数分布遵循整个键空间的分布。这样可以确保整个KV对访问计数的分布满足实际工作负载。另外,我们确保将热KV对紧密分配在一起。热键和冷键范围可以随机分配给整个键空间,因为键范围的位置对工作负载局部性的影响很小。
基于这些模型,我们进一步使用db_bench开发了一个新的基准测试。运行基准测试时,QPS模型控制两个连续查询之间的时间间隔。发出查询时,查询类型由从收集的工作负载中计算出的每种查询类型的概率确定。然后,键大小和值大小由拟合模型中的概率函数确定。接下来,根据每个键范围的访问概率,我们选择一个键范围来响应此查询。最后,根据KV对访问次数的分布,选择此键范围内的一个KV对,并使用其键来构成查询。这样,KV查询将由基准测试生成并遵循预期的统计模型。同时,它更好地保留了键空间的局部性。
比较基准测试结果
我们将ZippyDB工作负载调整为建议的模型(不包括删除),并建立一个称为Prefix_dist的新基准测试。为了评估基于键范围的建模的有效性,我们还实施了三个具有不同KV对分配的基准测试:1)Prefix_random对键范围的热度进行建模,但在每个键范围内随机分配热和冷KV对; 2)与YCSB相似,All_random遵循KV对访问计数的分布,但在整个键空间中随机分布KV对; 3)All_dist将热键放在整个键空间中,而不是使用随机分布。所有这四个基准测试达到了与ZippyDB相似的压缩率。
与第7.1节中描述的过程类似,我们将YCSB工作负载a和工作负载b配置为尽可能紧密地拟合ZippyDB工作负载。我们使用以下4种不同的请求分布来运行YCSB:1)均匀(YCSB_uniform),2)压缩(YCSB_zipfian),3)热点(YCSB_hotspot)和4)指数(YCSB_exp)。对于8个基准测试,我们使用相同的预加载数据库(具有5000万个随机插入的KV对,其平均键和值大小与真实工作负载的平均键和值大小相同)。RocksDB缓存大小与生产设置具有相同的值。
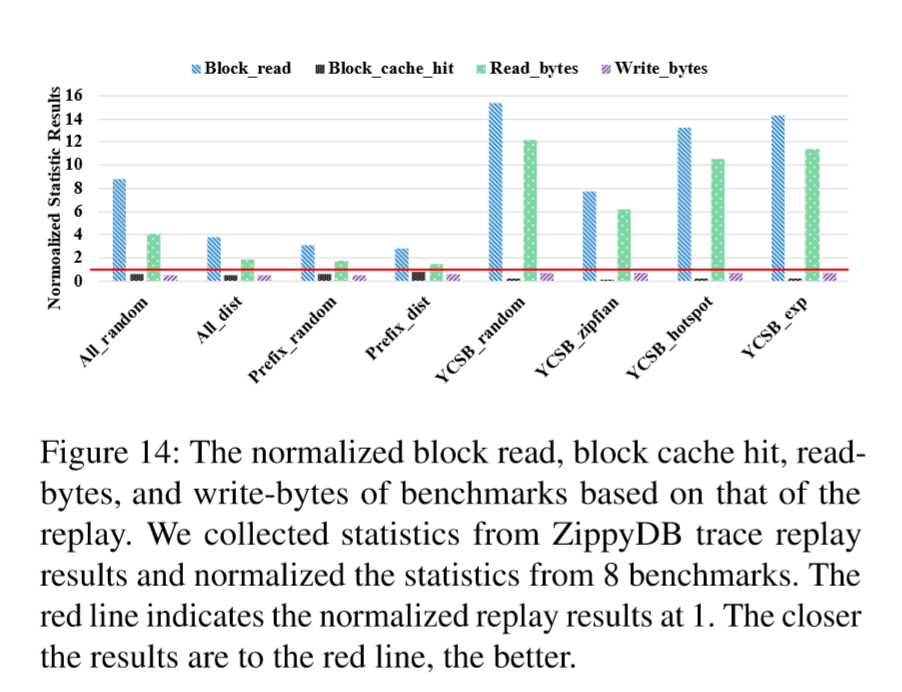
下图Figure 14比较了这8个基准测试的I/O统计信息。YCSB_zipfian的工作负载的块读取总数和读取字节数至少比原始重放结果高500%。更糟糕的是,其他三个YCSB基准测试结果的块读取数和读取字节数甚至更高,与重放结果相比,达到1000%或更高。相反,Prefix_dist的读取字节数仅高40%,并且最接近原始重放结果。如果我们比较实现的4个基准测试,可以得出结论,通过考虑键空间局部性,Prefix_dist可以更好地模拟存储读取的数量。All_dist和Prefix_random通过以不同的粒度(整个键空间级别与键范围级别)收集热KV对来减少额外的读取次数。请注意,如果YCSB达到类似的压缩率,则RocksDB存储I/O可以降低约35-40%。但是,这仍然比All_dist,Prefix_random和Prefix_dist的存储I/O差得多。
如果应用相同的压缩率,则YCSB的实际写入字节数应小于原始重放的50%。Prefix_dist可实现原始重放的大约60%的写入字节。实际上,与原始重放结果相比,键/值大小和KV对热度之间的不匹配导致写入字节更少。通常,可以通过以下方式进一步改进YCSB:1)添加基于键范围的分布模型作为生成键的选项; 2)提供吞吐量控制以模拟QPS变化; 3)提供键和值大小分布模型;以及4)增加模拟不同值压缩比的能力。
基准测试统计数据的检验
我们选择UDB中的Assoc工作负载作为另一个示例,以验证我们的基准测试是否可以实现与实际工作负载非常相似的KV查询统计信息。由于在Assoc中90%的键是28个字节,而10%的键是32个字节,我们可以使用这两个固定的键大小。我们发现,广义Pareto分布最适合值的大小和Iterator的扫描长度。在二项幂模型中,键范围的平均KV对访问次数可以更好地拟合,并且KV对访问次数的分布遵循可以拟合为简单幂模型。正如我们在第4.3节中讨论的那样,由于QPS变化具有很强的昼夜模式,因此它更适合于24小时周期的正弦模型。
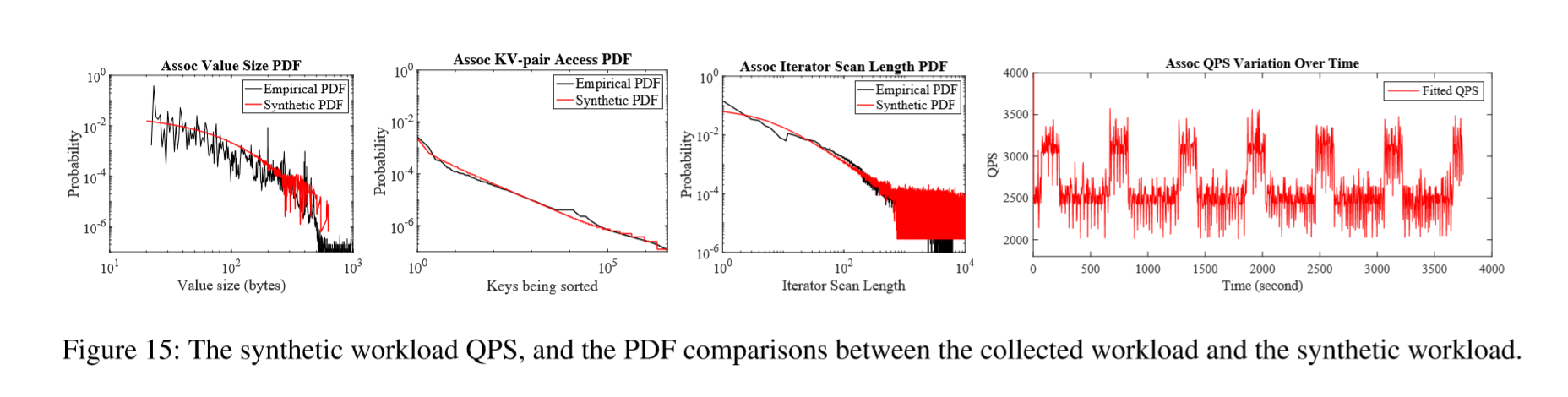
为了将通过基准测试获得的工作负载统计数据与实际工作负载的统计数据进行比较,我们以不同的工作负载规模运行新的基准测试。我们在基准测试期间收集跟踪并分析跟踪。下图Figure 15显示了UDB Assoc工作负载和生成的工作负载之间的值大小,KV对访问计数以及Iterator扫描长度的QPS变化和PDF(概率密度函数)比较。尽管从我们的基准测试中产生的工作量规模与UDB Assoc的规模不同,但PDF文件显示它们的分布几乎相同。这证明,就这些统计数据而言,生成的综合工作负载与UDB Assoc工作负载非常接近。
总结和未来工作
在本文中,我们介绍了Facebook上持久性KV存储工作负载的研究。我们首先介绍跟踪,重放,分析和基准测试的方法和工具。键/值大小分布,访问模式,键范围局部性和工作负载变化的发现提供了有助于优化KV存储性能的见解。通过比较以YCSB为基准的RocksDB的存储I/O和跟踪重放的存储I/O,我们发现以YCSB为基准产生的读取次数更多,写入次数更少。为了解决此问题,我们提出了一种基于键范围的模型,以更好地保留键空间的局部性。新的基准测试不仅可以在查询级别上很好地模拟工作负载,而且还可以实现比YCSB更精确的RocksDB存储I/O。
我们已经在最新的RocksDB版本中开源了跟踪,重放,分析和新的基准测试。新的基准测试是db_bench基准测试工具的一部分。我们目前还没有发布跟踪。将来,我们将通过键范围分布进一步改善YCSB工作负载的生成。此外,我们还将收集,分析和建模其他维度的工作负载,例如查询之间的相关性,KV对热度和KV对大小之间的相关性,以及其他统计信息,例如查询延迟和缓存状态。