ReFlex - Remote Flash ≈ Local Flash 论文笔记
Introduction
对NVMe Flash的远程访问实现了数据中心内Flash容量以及IOPS的灵活扩展和高利用率。但是,现有的用于远程Flash访问的系统会带来巨大的性能开销,或者无法隔离共享每个Flash设备的多个远程clients。
在实现对Flash的远程访问方面存在重大挑战。要实现低延迟,需要在server和client的网络和存储层上将处理开销降至最低。除了低延迟之外,每台服务器还必须以最低成本实现高吞吐量,从而使一个或多个NVMe Flash设备且具有少量CPU cores的机器达到饱和。此外,要管理共享一个Flash设备的多个租户之间的干扰以及Flash设备的不均匀读写行为,需要一种隔离机制,以保证所有租户的可预测性能。最后,在共享程度,部署规模和用于远程连接的网络协议方面需要具有灵活性。现有的仅软件用于远程Flash访问的选项(例如iSCSI或基于事件的服务器)无法达到性能预期。最近提出的硬件加速选件,例如基于RDMA架构的NVMe,缺乏性能隔离,并且部署灵活性有限。
我们提出了ReFlex,一个用于远程Flash访问的软件系统,其性能与访问本地Flash几乎相同。ReFlex使用数据平面内核紧密集成网络和存储处理,以在低资源需求下实现低延迟和高吞吐量。数据平面设计避免了中断和数据拷贝的开销,针对局部性进行了优化,并在高吞吐量(IOPS)和低尾部延迟之间取得了平衡。ReFlex包括一个QoS调度程序,该调度程序实现优先级和速率限制,以便为共享设备的多个租户实施针对延迟和吞吐量的服务水平目标(SLO)。ReFlex提供了用户态库和远程块设备驱动程序来支持client应用程序。
ReFlex服务器可以支持数千个远程租户。它的QoS调度程序可以通过SLO强制执行租户的尾部延迟和吞吐量要求,同时允许尽力而为的租户消耗NVMe设备的所有剩余吞吐量。
ReFlex是开源软件。该代码位于 https://github.com/stanford-mast/reflex。
Background and Motivation
远程访问提供了使用Flash的灵活性,而不管其在数据中心中的物理位置如何,从而提高了利用率并降低了总拥有成本。
远程访问硬盘在数据中心中已经很普遍,因为它们的高延迟和低吞吐量很容易掩盖网络开销(网络开销不是很明显)。各种软件系统可以使远程磁盘可用作块设备(例如iSCSI),网络文件系统(例如NFS),分布式文件系统(例如Google File System)或分布式数据存储(例如Bigtable)。还提出了使用远程直接存储器访问(RDMA)(例如NVMe over Fabrics)或PCIe互连进行硬件加速访问远程Flash的建议。现有的远程Flash访问方法面临两个主要挑战:以低成本实现高性能,以及在存在干扰的情况下提供可预测的性能。
Interference Management
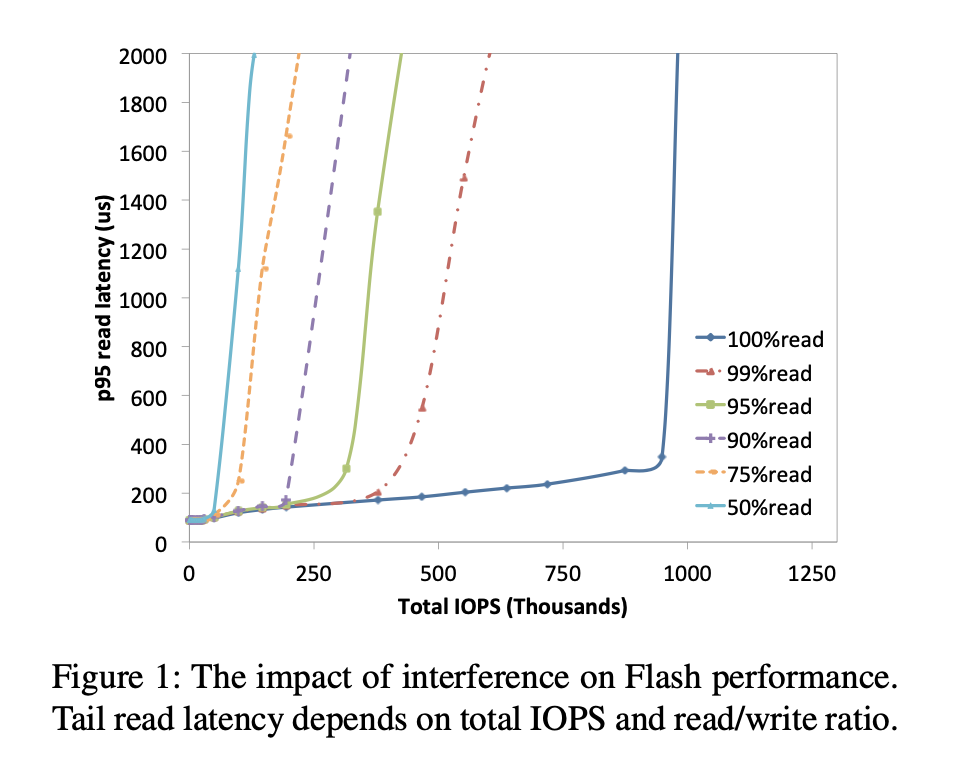
如果远程Flash即使多个租户共享一个设备也能提供可预测的性能,则很有用。由于读/写干扰的影响,可预测的性能对于NVMe Flash设备是一个挑战。图1绘制了Flash上的尾部读取延迟(第95个百分位数)与各种读写比率的工作负载的吞吐量(IOPS)的关系。尾部读取延迟取决于吞吐量(负载)和读写比率。对于我们测试过的所有NVMe Flash设备,此行为都是典型的,因为写入操作速度较慢,并且触发磨损平衡和垃圾回收活动,这些活动无法始终被隐藏。当单个应用程序使用本地Flash设备时,可以管理读/写干扰,但是对于远程Flash和共享同一设备但彼此不知道的多个租户而言,这成为一个巨大的挑战。
ReFlex Design
ReFlex使用紧密集成了网络和存储层的数据平面架构,提供了对远程Flash的低延迟和高吞吐量访问。它通过TCP和UDP等通用网络协议为任意大小的逻辑块提供远程读/写请求。ReFlex主要是软件系统,它利用NIC和NVMe Flash设备中的硬件虚拟化功能直接在硬件队列上运行,并有效地在NIC和Flash设备之间转发请求和数据,而无需拷贝。它的基于轮询的执行模型允许在不中断的情况下处理请求,从而提高了本地性并减少了不可预测性。ReFlex使用新颖的IO调度程序来保证具有不同读写请求比率的租户的延迟和吞吐量SLO。ReFlex可以为成千上万个租户和网络连接提供服务,使用所需的尽可能多的cores来使Flash设备IOPS饱和。
Dataplane Execution Model
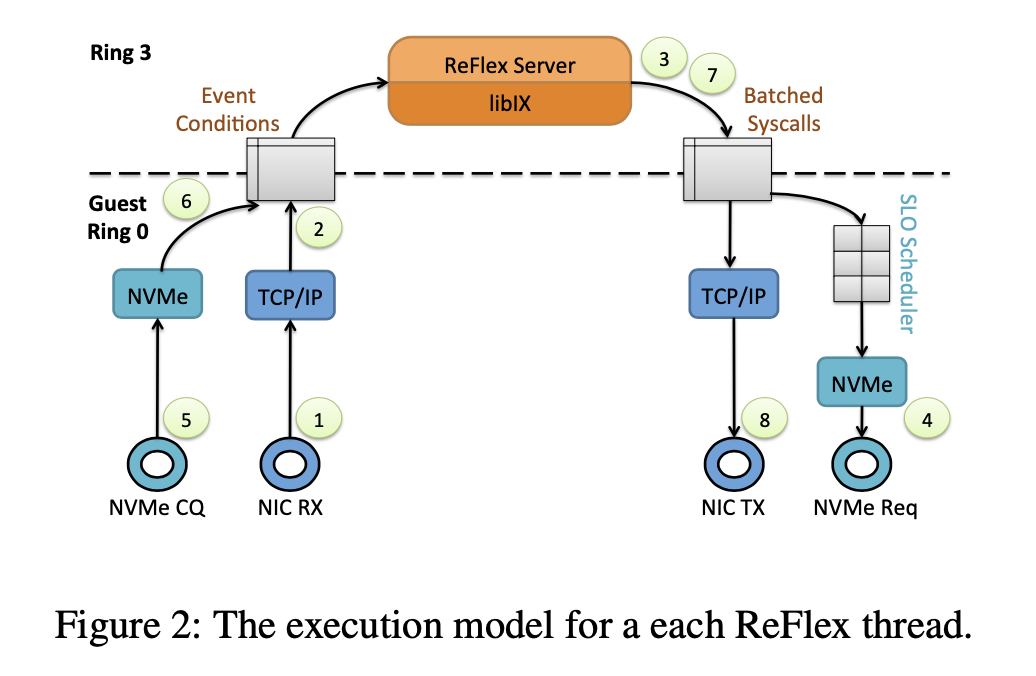
每个ReFlex服务器线程使用专用core,可以直接和排它地访问网络队列对以进行数据包的接收/发送,并使用NVMe队列对进行Flash命令的提交/完成。
图2展示了ReFlex服务器线程的执行模型,该线程处理传入的Flash读/写请求。首先,NIC接收网络数据包,然后通过DMA将其传送到网络栈提供的预分配的内存缓冲区(1)。ReFlex线程轮询接收描述符环,并通过以太网驱动程序和网络栈(例如TCP/IP)处理数据包,从而生成事件条件,指示新消息的可用性(2)。同一线程使用libix(类似于Linux libevent的库)来处理事件。这涉及切换到服务器代码,以解析消息,提取IO请求,执行访问控制检查以及提交Flash read/write系统调用之前所需的任何其他存储协议的处理(3)。然后,线程切换到系统调用处理并执行IO调度,以在共享ReFlex服务器的所有租户之间实施SLO。调度之后,请求将通过NVMe提交队列提交给Flash设备(4)。Flash设备执行读/写IO,并通过DMA将数据传送到预分配的用户空间缓冲区(或从预分配的用户空间缓冲区获取数据)(7)。线程轮询完成队列(5),并提供完成事件(6)。事件回调通过libix执行并发出send系统调用(7)。最后,线程处理send系统调用,以通过网络栈将请求的数据传递回发起方(8)。执行模型支持每条网络消息多个IO请求以及跨多个网络消息的大型IO。
QoS Scheduling and Isolation
QoS调度程序允许ReFlex为共享服务器中Flash设备的租户提供性能保证。租户是一种逻辑抽象,用于说明和执行服务级别目标(SLO)。SLO在特定吞吐量和读/写比率下指定尾部读取延迟的限制。例如,租户可以以80%的读取比率注册具有200us读取尾部延迟(95%百分数)的50K IOPS的SLO。除了此类延迟关键(LC)租户,这些租户在尾部延迟和吞吐量方面保证了分配,ReFlex还为尽力而为(BE)租户提供服务,这些租户可以机会使用任何未分配或未使用的Flash带宽并容忍较高的延迟。租户定义可以由成千上万的网络连接共享,这些连接来自运行任何应用程序的不同客户端计算机。应用程序可以使用多个租户为不同的数据流请求单独的SLO。
如图1所示,在Flash设备访问上强制执行SLO有两个因素。首先,设备可以支持的最大带宽(IOPS)取决于它在所有租户中看到的请求的总体读写比率。其次,读取请求的尾部等待时间取决于总体读取/写入比率和当前带宽负载。因此,QoS调度程序需要全局可见性和对Flash上的总负载以及未完成的IO操作类型的控制。我们使用请求成本模型来说明每个Flash IO对读取尾部延迟的影响,并使用一种新颖的调度算法来保证所有租户和所有数据平面线程之间的SLO。
Request Cost Model
该模型估计读取尾部延迟是加权IOPS的函数,其中请求的成本(权重)取决于I/O size,I/O type(读取与写入)以及当前设备上的读/写请求比率r:
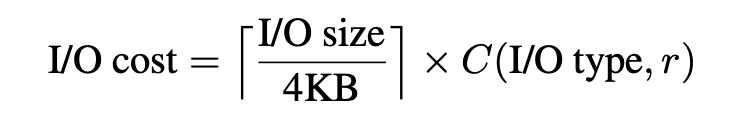
成本是r的函数,因为相对于读负载为99%或更低的情况,某些闪存设备对只读负载(r = 100%)提供了更高的IOPS,如图1所示。因此,该模型调整了设备负载为只读时的读取请求。成本以token的倍数表示,其中一个token代表4KB随机读取请求的成本。在我们使用的所有Flash设备中,对于大于4KB的大小,成本都会随着请求大小线性增长(例如,一个32KB的请求的成本高达8个连续4KB的请求)。对于4KB及以下的请求,成本是恒定的,因为这些Flash设备似乎以4KB的粒度运行。
我们针对ReFlex服务器中部署的每种类型的Flash设备校准成本模型。首先,对于具有各种读写比率和请求大小的工作负载,我们使用本地Flash测量了尾部等待时间与吞吐量的关系(请参见图1中的4KB示例)。由于写入请求的成本取决于垃圾回收和页面擦除事件的频率,因此我们保守地使用随机写入模式来触发最坏的情况。接下来,我们使用曲线拟合来得出C(I / O type,r),尽管非线性曲线拟合模型可以实现更好的拟合,但是为了简单起见,调度程序采用线性模型,因为线性模型的精度足够了。部署后可以重新校准模型,以解决由于闪存磨损而导致的性能下降。
根据不同的Flash设备,写操作往往比读操作多出10-20倍的成本,即一次写操作需要10-20个token,C(write, r < 100%) = 10 tokens ~ 20 tokens。如图1所示,相比于99%或者更低读写比的负载,某些Flash设备对只读负载 (r = 100%) 提供了更高的IOPS。对于只读负载,模型需要调整读请求的成本,一次读请求只需要其他负载下一半的成本,C(read, r = 100%) = 1/2 token。
Scheduling Mechanism
QoS调度器构建在成本模型之上,保持延迟关键租户的尾端延迟和吞吐量的SLO,同时允许尽力交付型租户以公平的方式利用剩余的吞吐量。
token管理
ReFlex调度以等于Flash设备在给定尾端延迟SLO上可以支持的最大加权IOPS(上述的成本模型)的速率生成token。ReFlex在所有共享一个Flash设备的延迟关键租户中执行最严格的延迟SLO。在它们的SLO指示的读写比加权情况下,延迟关键租户被提供能够满足它们IOPS SLO的token供应。由调度程序生成但未分配给延迟关键的token将在尽力交付型租户之间公平分配。当调度程序将租户的请求提交到Flash设备时,它会根据每个请求的成本来花费租户的token。
调度算法

每个ReFlex线程将Flash请求排入每个租户的软件队列中。当线程到达数据平面执行模型中的QoS调度步骤时,线程使用算法1计算排队请求的加权成本,并将所有允许的请求提交给Flash设备,从而逐渐花费每个租户的token。根据线程负载和批处理因子,执行模型每0.5us至100us进入一次调度回合。通过对控制平面和批处理大小限制确保调度程序调用之间的时间不超过最严格SLO的5%。必须进行频繁的调度,以避免过多的排队延迟并保持NVMe设备的高利用率。
其次,ReFlex采用自适应批处理请求,以分摊开销并提高预取和指令缓存效率。在低负载下,将立即处理传入数据包或已完成的NVMe命令。随着负载的增加,NIC接收和NVMe完成队列将填满,并为批量处理多个传入数据包或多个完成的访问提供了机会。批大小随负载增加而增加,但上限为64,以避免过多的延迟。不同于传统的批处理,后者需要在带宽和延迟之间进行权衡,自适应批处理在高吞吐量和低延迟之间实现了良好的平衡。
延迟关键(LC)租户
调度算法首先服务延迟关键租户。首先,调度程序根据每个LC租户的IOPS SLO和自上次调度程序调用以来的经过时间来为每个LC租户生成token。由于控制平面已确定每个LC租户的加权IOPS预留是可接受的,因此调度程序通常可以将所有LC租户的排队请求提交到NVMe设备。但是由于流量很少统一,并且租户发出的IOPS可能比其SLO中保留的平均IOPS少或多,因此调度程序会跟踪每个租户的token使用情况。算法允许LC租户暂时突破其token分配,以避免短期排队,但是一旦租户达到token不足限制(NEG_LIMIT),算法通过限制LC租户的速率来限制突破的大小。NEG_LIMIT参数通常设置为-50个令牌,以限制突破中昂贵的写请求的数量。当达到此限制时,我们还会通知控制平面,以检测具有错误SLO租户,以重新协商。
消耗少于它们被提供的tokens的LC租户可以为以后的突破积累tokens,积累被参数POS_LIMIT限制。到达参数限制时,调度程序将大部分累积的tokens(经验上为90%)捐赠给全局令牌存储区,以供BE租户使用。根据经验,POS LIMIT设置为LC租户在最近三轮调度中收到的令牌数量,以适应短暂的突发事件而不会出现赤字。
尽力交付(BE)用户
调度程序通过为每个BE租户分配设备上未分配吞吐量的公平份额来生成BE租户的token。未分配的设备吞吐量与设备在执行最严格的LC延迟SLO减去LC租户令牌率之和(基于LC租户IOPS SLO)时可支持的令牌率相对应。假设有N个BE租户,每一轮调度回合,每个BE租户都将收到未分配token率的1/N乘以自上一个调度周期以来所经过的时间。如果BE租户没有足够的token来提交其所有入队的请求,则租户可以从全局token桶中索取tokens,这些tokens有由带有闲置tokens的LC租户提供。BE租户在各个调度回合中以循环顺序进行调度,以提供对全局token存储区的公平访问。仅当租户具有足够的token用于请求时,调度程序才会提交BE请求。
限速BE流量对于实现LC SLO至关重要。由于调度回合以高频率发生,因此典型的回合可能仅生成令牌的一小部分。当BE租户的请求队列不为空时,它们会在多个调度回合中累积令牌。当BE租户的软件队列为空时,我们禁止令牌累积来防止在空闲时间后突发。调度程序的这一方面是受赤字循环调度调度的启发。BE租户未使用的令牌将捐赠给全局令牌存储区,以供其他BE租户使用。为了避免大量积累,使BE租户能够发出不受控制的突发事件,我们会定期重置存储桶。