IX - A Protected Dataplane Operating System for High Throughput and Low Latency 论文笔记
Introduction
用户态网络栈
传统观点认为,积极的网络要求,例如小消息的高数据包速率和微秒级的尾端延迟,最好在用户态网络栈中进行处理。用户态网络栈消除了上下文切换的开销,但是并没有消除高数据包速率和低延迟之间的艰难权衡;同时也会缺乏保护,用户程序的bugs会污染网络栈。
IX简介
IX,一个data plane操作系统,旨在达到高吞吐量,低延迟,强大的保护和资源效率这四个权衡。IX使用硬件虚拟化来分离control plane(内核的管理和调度功能)和data plane(网络处理)。
IX利用Dune和虚拟化硬件以不同的保护级别运行data plane内核和应用程序,并将control plane与data plane隔离。 在我们的实现中,control plane是完整的Linux内核,data plane在专用的硬件线程上作为受保护的基于库的操作系统运行。
这个data plane架构建立在本地的零拷贝API之上,通过将硬件线程和软件队列专用于data plane实例、处理有限的批量数据包至完成(run-to-completion)、消除了一致性流量和多核同步,从而优化了带宽和延迟。
IX API不同于POSIX API,其设计遵循可交换性规则。但是,libix用户级库包含类似于流行的libevent库的基于事件的API,可与多种现有应用程序兼容。
IX演示了通过重新访问网络API并利用现代NIC和多核芯片的优势,我们可以设计出实现高吞吐量和低延迟以及强大的保护和资源效率的系统。它还表明,通过将性能关键型IO功能的较小子集与内核的其余部分分开,我们可以构建与众不同的IO系统,并获得较大的性能提升,同时保持与由OS提供的庞大的API和服务的兼容性。
我们证明了IX在吞吐量和端到端延迟方面均明显优于Linux和最新的用户态网络栈。
IX的两点贡献:通过虚拟化实现保护和直接硬件访问;低延迟和高吞吐量的执行模型。
Implementation
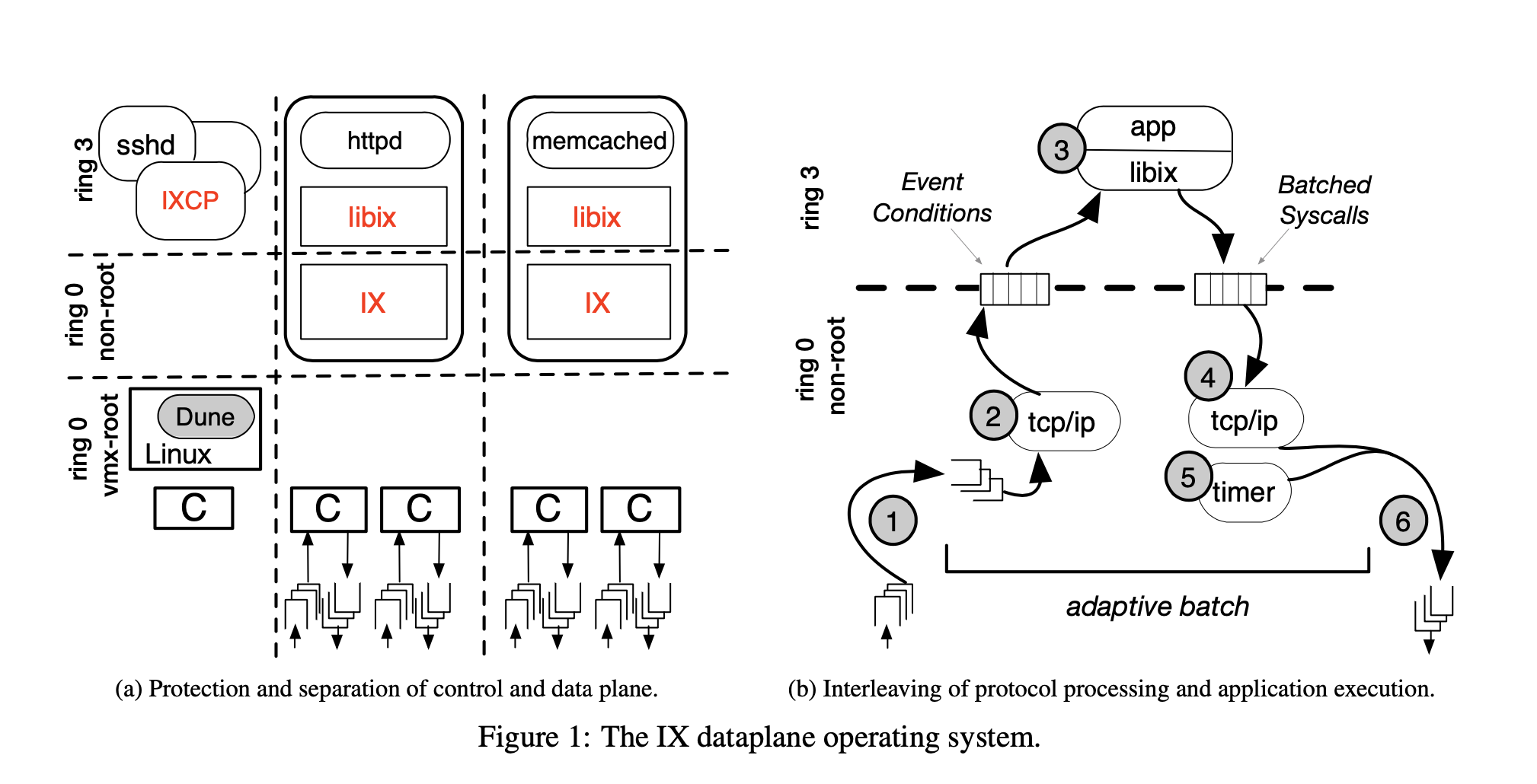
Overview
图1(a)显示了IX架构,重点是control plane和多个data plane之间的分离。
IX的control plane由完整的Linux内核和IXCP(用户级程序)组成。 Linux内核初始化PCIe设备(例如NIC),并提供用于向data plane分配资源的基本机制,包括core,内存和网络队列。同样重要的是,Linux提供了与多种应用程序兼容所必需的系统调用和服务,例如文件系统和信号支持。IXCP监视资源使用情况和data plane性能,并实施资源分配策略。
我们在VMX root ring 0中运行Linux内核,该模式通常用于在虚拟化系统中允许hypervisor。我们在Linux中使用Dune模块,使data plane能够在VMX not-root ring 0中作为特定于应用程序的OS运行,该模式通常用于在虚拟化系统中运行guest内核。像往常一样,应用程序在VMX ring 3中运行。 这种方法为data plane提供了对硬件功能(如页表和异常)的直接访问,以及对NIC的直通访问。此外,它在control plane,data plane和不受信任的应用程序代码之间提供了全面的三向保护。
每个IX的data plane都支持一个多线程应用程序。例如,图1a显示了用于多线程Memcached服务器的一个data plane和用于多线程httpd服务器的另一data plane。control plane以粗粒度方式将资源分配给每个data plane。核心分配是通过实时优先级和cpusets控制的;内存以大量页分配;每个NIC硬件队列都分配给单个data plane。这种方法避免了在要求苛刻的应用程序之间进行细粒度的时间复用的开销和不可预测性。
IX Dataplane
IX的data plane目前由39K SLOC组成,并利用了一些现有的代码库:41%源自Intel NIC设备驱动程序的DPDK变体,26%源自lwIP TCP/IP堆栈,15%来自Dune库。我们没有使用DPDK框架的其余部分,并且为IX高度修改了所有三个代码库。其余的大约是新代码的7K SLOC。 我们选择lwIP作为TCP / IP处理的起点,因为它的模块化和作为RFC兼容,功能丰富的网络堆栈的成熟性。我们为UDP,ARP和ICMP实现了自己的RFC兼容支持。
我们构建了一个名为libix的用户级库,该库抽象了底层API的复杂性。它为旧版应用程序提供了兼容的编程模型,并大大简化了新应用程序的开发。libix当前包括一个与libevent和非阻塞POSIX套接字操作非常类似的接口。它还包括用于零拷贝读取和写入操作的新接口,这些接口效率更高,但需要更改现有应用程序。
run-to-completion operation
每个IX的data plane都作为单个地址空间OS运行,并在共享的用户级地址空间内支持两种线程类型:与IX的data plane交互以启动和使用网络IO的弹性线程;以及背景线程。
图1(b)说明了IX的data plane中弹性线程的run-to-completion操作。 NIC接收映射到服务器的主内存中的缓冲区,并且NIC的接收描述符环中填充了一组缓冲区描述符,允许它使用DMA传输传入的数据包。弹性线程(1)轮询接收描述符环,并可能将新的缓冲区描述符传到NIC,以用于将来的传入数据包。然后,弹性线程(2)通过TCP/IP网络栈处理一定数量的数据包,从而生成事件条件。接下来,线程(3)切换到用户空间应用程序,该应用程序消费所有事件条件。假设传入的数据包包括远程请求,则应用程序将处理这些请求并以一批系统调用作为响应。从用户空间返回控制后,线程(4)处理所有的批量系统调用,尤其是那些直接控制传出TCP/IP通信的调用。线程还(5)运行所有内核计时器,以确保符合TCP行为。最后(6),它将传出的以太网帧放置在NIC的发送描述符环中进行传输,并通知NIC通过更新发送环的尾部寄存器来启动这些帧的DMA传输。在单独的传递中,它还会根据传输环的头部位置释放所有已完成传输的缓冲区,从而有可能生成已发送的事件条件。循环重复此过程,直到没有网络活动为止。在这种情况下,线程将进入沉默状态,该状态涉及超线程友好的轮询,或者可选地进入省电的状态,这是以额外的延迟为代价的。